Building An Autonomous Battlebot (Part 1)
Humans & Robots
Piloting a robot with a computer can have many advantages over a human; humans are slow to react, imprecise with their movement, and are prone to making mistakes under pressure. Computers, on the other hand, can react quickly, precisely, and make no mistakes (any mistake is the fault of the programmer!). Humans have one key advantage, however, and that is our adaptability. We rely on our intuitions of the physical world and our understanding of cause-and-effect to navigate and adapt to our enviroments every day. We demonstrate these intuitions with subconscious, routine actions, like when we precisely place our feet as we walk up a flight of stairs, or knowing the precise amount of force required to lift an object based solely on looking at it. We also rely on these intuitions with conscious actions, like in sports, where you often need to predict where a flying ball will land based on its current trajectory, or how we just know where (and how hard) we must begin braking a car approaching a red light. Computers do not have this intuition; they are at the whim of the programmer’s ability to translate their own human intuitions into code. A great programmer can embue their algorithms with enough of these intuitions to handle many edge cases, but the effort this requires increases exponentially with the scope of the task. Generalizable robots and algorithms run the highest risk of unsolved edge cases, while narrow task-specific systems have the lowest chance of unforeseen edge cases. Thus, instead of trying to write extra algorithms to solve possible edge cases, we must reduce the amount of edge cases in the first place, either by decreasing the scope of the task, or by adopting a control philosophy that inherently reduces the possibility of edge cases occuring. With all of that, this introduces two ideas that I think are essential to creating an effective autonomous combat robot: first, we must adopt a control philosophy that has a small enough scope while still being versatile enough to win fights, and second, we must avoid mimicking human strategies so that we can fully utilize the benefits of computer controls.
Autonomous Combat Theory
In the context of combat robotics, our ability to adapt to unique situations is often very helpful. Most drivers would tell you that combat robotics takes Murphy’s Law to the extreme. It is entirely expected to see new “firsts” in basically every high-energy fight. Humans can handle these novel situations, but computers (especially ML models) inherently rely on pattern matching to know how to act. A human driver can often easily tell how a stuck robot needs to move to get unstuck, or if it will not be able to unstick itself at all. Determining these kinds of physical details reliably with solely a computer algorithm is functionally impossible within the scope of this project. So, if our opponent puts us in a state where the computer cannot reliably determine what to do or what the state of the robot even is, we have no choice but to just flail around, and if that doesn’t solve whatever the issue is, we lose. There is one easy solution to this issue: maintain total control of the fight to prevent the opponent from putting our bot in a situation the computer doesn’t know how to handle. This is much easier said than done.
So how do we prevent humans from gaining an upper hand, then? We act erraticly, ensure unpredictability, and make movements that are far beyond the expected behavior of a human driver. If humans cannot predict what the bot does next, it becomes very difficult to counter. As discussed earlier, this is the major benefit of a computer-controlled bot: we can drive very fast and erratic, yet maintain precise control the entire time. Even the best human drivers get confused sometimes, and can only handle so many controller inputs per second, but a computer can vary inputs thousands of times per second to ensure the robot is doing exactly what it wants.
Kiwi Drive
To follow this strategy of randomness and confusion, I decided on a kiwi drive motion platform. Kiwi drive is a type of holonomic drive, which means that it can move in any direction while facing any direction. This significantly increases the mobility of the robot compared to the standard tank drive that many combat robots use. Tank drive does not allow for significant rotation while moving forward or backwards, and high level driving with it requires significant skill. This is in part due to the gyroscopic procession that occurs when robots with a spinning weapon attempt to turn, which causes the robot to tilt upwards and lose traction. Kiwi drive does not prevent this gyroscopic procession, but it does have a signifcantly wider footprint which reduces the amount of tilt. However, because we are using holonomic drive, we can turn the bot while we move towards the opponent, giving us more time to turn during an attack, which allows us to rotate slower, reducing tilt.
 Kiwi Drive vs. Tank Drive
Kiwi Drive vs. Tank Drive
Combat Robotics Scoring & Strategy
How does someone actually win a combat robotics fight? In the NHRL ruleset, there are three scoring categories: Aggression (5 points total), Control (6 points total), and Damage (6 points total) (defined below). The judges will allocate points from each of these categories between the two competitors, and then sum all three categories for a final score (up to 17 points). The bot with the highest score from 2/3 judges wins the match.
Points Categories
- Aggression: Did you attack your opponent frequently and substantially?
- Damage: Did you disable key components on your opponent?
- Control: Did you physically control your opponent or cause them to get stuck?
Aggression is the easiest to score points with via autonomous control, because ramming your opponent with your weapon requires significantly less precision than actually controlling them, and you may still gain aggression points without a working weapon.
Damage is less directly related to driving than aggression. Damage is primarily related to how effective your weapon is at delivering kinetic energy into your opponent, and how well you can manuever to attack their less armoured components. The more energy your weapon can put into the opponent, the more damage it can do. This is highly dependent on many factors, but primarily depends on weapon geometry and weapon speed. Weapon design is a very deep rabbit hole that I will not be getting into, but suffice to say, it can be complicated and sometimes very unintuitive. As far as autonomous control goes, damage really just depends on being precise enough to specifically aim towards the less armoured areas of your opponent.
Control is by far the hardest category to score points on with autonomous control. Currently, there is not really any real time way to determine the granular physical state of any robot in the arena. How could you differentiate between your weapon blade getting stuck in the wall and getting stuck on top of a piece of debris while next to the wall? Both prevent you from easily moving away from the wall, yet, it would be basically impossible for a computer to tell the two apart, especially when considering the whole system needs to be efficient enough to compute everything in real time (no GPT-4, sorry!). You might have some clever solution to this specific problem, but there are dozens of these gotchas. Fights are so incredibly unpredictable, so you will never be able to plan for every single scenario that will occur in the arena. So how does this relate to control points? Well, it’s not even really that easy to tell if you are pinning your opponent or if they are pinning you. Once you figure out whether you are doing the pinning or getting pinned, you still can’t easily determine what orientation and specific movements may be needed to continue pinning an opponent. Are you going to drive up over them if you keep moving forward? Or do you need to actually back up and re-pin them for a more stable pin? It’s practically impossible for a computer to tell.
My current goals for autonomous control do not include pinning opponents. I just think it’s too hard to execute pins properly, and I’m especially against trying it when being aggressive and causing damage is easier and likely more effective for autonomous control.
My (WIP) Autonomous Architecture
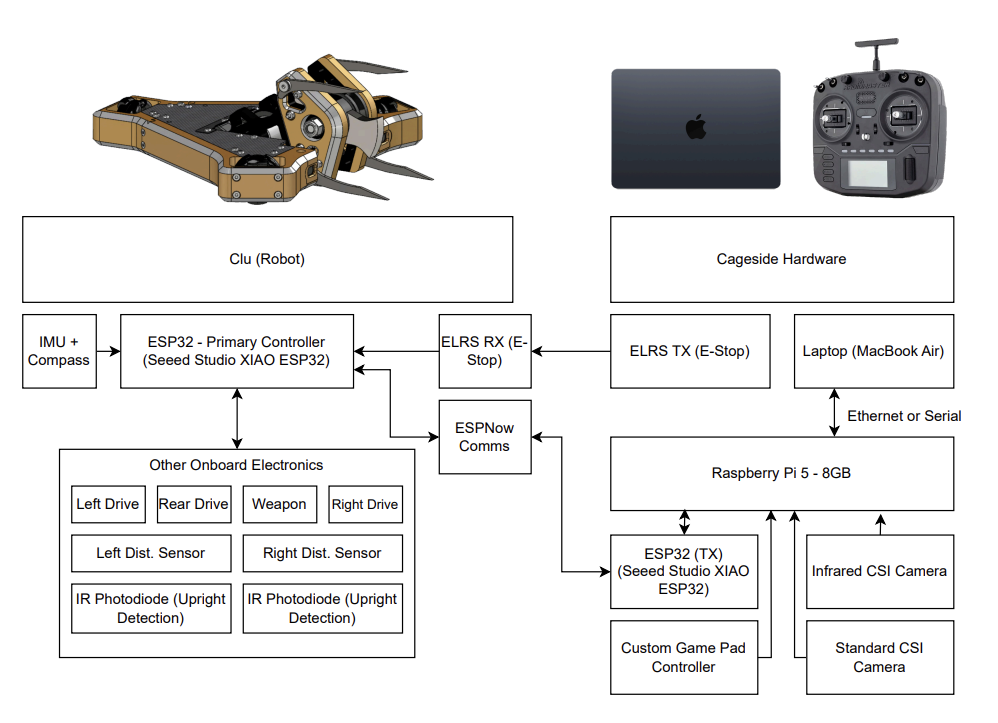 Most of the hardware needed to run this architecture
Most of the hardware needed to run this architecture
Hardware
I am using Clu, my 3lb beetleweight combat robot, for this autonomous framework. You can read more about Clu in my blog post about fighting with it at NHRL.
External Sensors
My system currently uses two external cameras: one with an infrared-only lens, and one with a standard lens. We feed the standard camera into a custom-trained YOLOv8 object detection model which outputs bounding boxes for full size robots, minibots, housebots, wheels, belts, and generic debris. We can get about 40fps with this model on my Macbook Air M3 (which I intend to use cageside for real fights), and it is used as our primary source of arena state data. A 40Hz refresh rate is okay for feeding control algorithms, but it’s not great. It will give us a 25ms response time at best, which is still 10x better than a human’s ~250ms reaction time, but it could still get better. Hence the second (infrared) camera for higher frequency data. We use the infrared camera to track the precise position of our robot in the field by putting retroreflective tape on the robot and blasting it with IR. The tape reflects the IR, which is then picked up by the camera, allowing us to track our robot’s position with much higher accuracy and refresh rate (due to the lower computational overhead of pure computer vision vs. a full ML model).
![]() An early example of tracking on-robot IR markers
An early example of tracking on-robot IR markers
My testing has shown we can get ~100Hz refresh rate with this system with reasonable accuracy. This is actually a very simplified version of what externally-sensed motion tracking systems have used for decades. Basically all motion capture systems have used nearly this exact technique of putting simple IR retroreflectors on humans and kept the bulky, expensive sensors positioned outside the capture area. They just use hundreds of thousands of dollars of camera equipment and have developed MUCH better software. This simple version should work fine for my purposes though, because I really just need X/Y tracking while the robot is on the floor. It will only ever need to track 2D motion, and there shouldn’t be any obstruction of the tracking markers (in theory). Because of these simpler requirements, I can use a single camera and pretty easily build a map of positions of camera pixels to physical points in the arena. With one camera, I can only track 2 degrees of freedom (X and Y on the floor of the arena), so I won’t be able to track the robot midair, but this is fine, because I don’t need to know where the robot is in 3D space midair, only that it is in the air at all.
Internal Sensors
Onboard Clu, we have an IMU, gyroscope, wheel speed sensors, and two front-facing distance sensors. The IMU and gyro give us very high frequency motion data, that when combined with the lower frequency external camera tracking, allows the real time control algorithm to very precisely control the position and velocity of the robot. Our wheel speed sensors contribute to this movement data, but also lets the control algorithm figure out if one of our drive motors have stopped spinning for whatever reason (which is a very common occurence in combat robotics). If we know a wheel has stopped spinning, we can change to a different, defense-focused drive strategy. Finally, we have two Time-of-Flight (ToF) distance sensors facing the front of the robot. These are useful for finely controlled attacks on an opponent, because it allows us to verify we are hitting them straight on. They also act as a sanity check if our external tracking is giving bad data, because we will always be able to find the distance to the closest front-facing object, which we can check against what we would expect from our tracking data.
Control Strategy
With all of this in mind, I have come up with four guiding ideas when it comes to implementing control logic:
- Minimize Danger
- Don’t get hit and don’t let your opponent score points
- Don’t Be Predictable (Don’t Be Human)
- Take advantage of holonomic drive and computer control with controlled chaos and unpredictability
- Maximize Aggression
- Gain as many points as possible by smothering opponent with constant attacks
- Punish Opponent’s Mistakes
- If an opponent makes a mistake we must immediately take advantage of it
Offensive Strategy
After reviewing many of the best combat robot drivers’ fights, I decided to go all in on one offensive strategy: smothering the opponent to the point that they never get a chance to attack you back. If you never let your opponent into a stable state, they can never find their bearings and attack you. This is especially important with particularly dangerous spinners, because when you don’t let their weapon spin up, they can never hit you with their full power. Two great examples of bots that use this strategy are Eruption and Lynx: both are vertical spinning “beater bars”, which are generally the most efficient vertical spinning weapons for maximum energy transfer. These two bots are unquestionably some of the best beetleweight combat robots to ever exist, and they are both known for their devastatingly effective driving. Their strategy has a very high skill requirement, though: with tank drive (which both of these robots use), when you go to line up a shot, you must perfectly align yourself, and then hit the gas and hope you hit the opponent. This is because you cannot really turn at all while driving forward due to the gyroscopic effects of a vertical weapon mentioned earlier. Once you start moving forward, you either hit your opponent, or come to nearly a full stop and rotate towards them again. You must repeat this over and over with absurd precision, which is difficult for even the absolute best human drivers. This problem is solved for us in two ways, however. First, as discussed, computers can just tell exactly how they need to position themselves to be perfectly aligned towards their opponent, within the error of the tracking system. Second, we are using kiwi-drive, which allows us to (somewhat) modify our trajectory while driving towards our opponent. We still have some limit on how fast we can rotate, but we can translate side to side to without issue, giving us the ability to correct for an opponent moving or a bad initial trajectory.
 Lynx & Eruption
Lynx & Eruption
Not only is “ram the hell out of your opponent” rather easy to implement, but it can still be successful despite less-than-perfect tracking precision, making it perfect as a primary offensive strategy. It is very likely that the precision of the vision-based tracking will not be great at first, so it is important to begin with a simple strategy that can still work despite some issues. Ideally we will be tracking the orientation of our opponent (we can get ours by fusing our onboard sensors and external tracking) with the YOLO object tracking model, but this is a difficult task, and I am not confident we will be able to get consistently accurate orientations in the first run of this system. If we do have the orientation of opponents, however, we will try to move in an arc that brings us to the opponent’s side, instead of ramming them head on and possibly going weapon-to-weapon. Weapon-to-weapon exchanges can be fine if you have designed a very robust weapon assembly, but that is not a given, especially when I am a less experienced bot builder, so it is best to avoid such a high-energy collision when possible.
Defensive Strategy
We’ve talked about offense a lot, but defense is just as important: regardless of how aggressive we are, there will be a point where our opponent attempts to attack us. What do we actually want to do when an opponent is driving straight at us, weapon screaming? First, of course, we need to get out of the way. That’s not particularly difficult given a high frequency tracking system to inform us of the opponents’ movements. We’ll never be perfect, so we will certainly still need armor, but we’ll always react faster than a human, which will give us an inherent advantage. Additionally, because we are using kiwi drive, we can simply just make one movement and strafe out of the way.
The defense strategy I had initially thought up was called “Hills of Danger”. The general idea was to create a 2D heatmap on the arena floor where each cell represented the danger value of its corresponding location. Each wall, enemy, and piece of debris would increase the danger level of the cells where they were physically located. Then, we imagined each cell would be as tall as its danger value, so dangerous areas of the arena would be much taller than safer areas. So, if you were to place a ball on the most dangerous area of the arena (the tallest “hill”), it would roll down the hill to the safest area. Our robot is the ball and the danger within the arena is where our opponent is currently located, as well as where we predict they are moving to in the future. This way, we can continuously avoid dangerous areas in the arena by “rolling down the hill”.
This was not a novel idea, and there is an existing algorithm called Potential Fields that accomplishes the same idea slightly differently, but with many improvements. Each dangerous entity in the arena will “push” the robot away, like a positive magnetic field would push a negative field away. These “push” forces are added together to create an acceleration force on our robot which moves it away from the sum of the danger in the arena. I also made a few modifications I’ve made to prevent the robot from finding an equilibrium and staying still, such as adding a constantly changing goal force which “pulls” the robot towards a safe area of the arena.
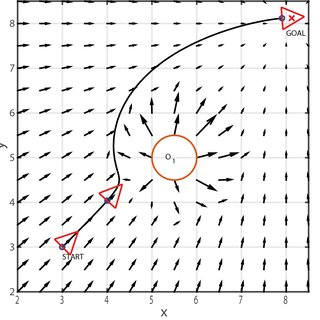 Potential Fields Goal & Defense Planning - Courtesy of Denis Konstantinov
Potential Fields Goal & Defense Planning - Courtesy of Denis Konstantinov
Control Software
To run the realtime controls for this project, I created a Python framework for managing all the sensors and control algorithms that run the robot. All of my robots have had a Daft Punk themed name, so to match, I called this architecture AutonomousAfterAll (AKA A3). A3’s primary software component runs on my laptop outside of the cage and handles both of the external cameras and the related ML+CV pipelines for each camera, and then communicates with the robot to send the tracking data from them to the bot.
The secondary goal of this entire project is to make all software and hardware components open source so that the rest of the combat robotics community can use and expand on this framework. Right now A3 (and the entire project…) is very much still a work in progress, but I am hoping to compete with it during the 2025 NHRL season, and I plan to open source it once I actually compete with it.
A3 is composed of four major components:
External
- External Tracking Handler
- Computer Vision + ML/AI Processing
- External State Handler
- Makes most decisions on state changes based on external tracking
Onboard
- Onboard Tracking Handler
- Keeps track of internal sensors and fuses external tracking data
- Onboard State Handler
- Makes low-latency decisions to change state based on fusion of internal and external sensor data
- Manages driving and weapon control
The external state manager will make decisions to change between states over a longer timeframe, such as when our battery is dying and we need to engage the defensive state more. The onboard manager will use its lower latency sensors to make time-critical state changes, such as turning to face an opponent that has initiated an attack and is quickly closing distance. It would be much simpler if all of this processing could be done onboard with a dedicated processing unit, but there is simply no processor physically small enough with low enough power requirements that can provide the compute needed to run the ML/AI algorithms running the tracking systems. These 3lb bots are rather tiny with very little internal space, and requiring a larger battery will only reduce the available space. I’d absolutely love to put this system onboard a larger bot, but the cost of a competitive 3lb is already almost too much for me.
At the moment, I have nearly finished the external systems (tracking & state management), but the onboard systems need some more attention. This is mainly because I began working on the external tracking system, since it was the most difficult of the major components. Then, I began working on the external state management in order to test the tracking system, as I was in France for the summer without access to any of my robot hardware and electronics equipment. I’ve implemented the potential fields defensive strategy, as well as what I call the “bullet” offense, which is basically just picking the enemy that is best to just… drive straight into. This makes sure there is no other debris/enemy/etc in the way of us and this picked bot. Then we just drive into them full speed with our weapon.
 Simulation of offensive / defensive strategies on a tracked fight
Simulation of offensive / defensive strategies on a tracked fight
Going Forward
I’m hoping to finish an initial, working implementation of these ideas for the 2025 NHRL season. I have a new hardware revision of Clu that is ready to be built on, so driving and tracking tests should begin soon. I will be sharing this progress as a part 2 whenever it is ready. Part 3 will hopefully be a demonstration of full, complete capabilities, and part 4 will be a postmortem after competing.
See you then!
Max
Credits / Attribution
Potential Fields Graph - Copyright Denis Konstantinov - https://clover.coex.tech/en/obstacle-avoidance-potential-fields.html - https://creativecommons.org/licenses/by-nc-sa/4.0/